Avoimen datan tekninen viitekehys
Tekninen viitekehys
Avoimen datan tekninen viitekehys määrittelee avoimen datan Avoindata-palvelun näkökulmasta. Se on elävä dokumentti, josta iteroidaan versioita Google Docsissa olevasta luonnosversiosta.
Tutustu luonnosversioon (Google Docs -dokumentti).
Avoimen datan asiat ovat jatkuvassa muutoksessa ja siksi tekninen viitekehys tulee päivittymään tämän luonnosdokumentin perusteella säännöllisesti.
Viimeisin julkaistu versio on 1.0 luonnos.
FAIR-periaatteet
Avoimen datan julkaisussa tulisi varmistaa mahdollisuus datan mahdollisimman laajaan uudelleenkäyttöön. Silloin avattu data tuottaa yhteiskuntaan mahdollisimman paljon hyötyä. Laadukkaamman datan julkaisemisen tueksi on julkaistu kansainvälisesti FAIR-periaatteet vuonna 2016.
FAIR-lyhenne tulee sanoista Findable, Accessible, Interoperable ja Re-usable. Se tarkoittaa, että lähdeaineistojen, menetelmien ja tietotuotteiden tulee olla löydettävissä, saavutettavissa, siirrettävissä tai yhdistettävissä ja uudelleenkäytettävissä.
FAIR-periaatteiden soveltamista avoimen datan tietoaineistoihin kannattaa ja suosittaa esimerkiksi Euroopan unioni. FAIR-periaatteet on mainittu myös avoimen datan direktiivin artiklassa 10. Näiden periaatteiden soveltaminen käytäntöön ei ole täysin suoraviivaista ja helppoa, vaan vaatii muutoksia dataa avaavan organisaation toimintatapoihin.

FAIR-periaatteiden toteutumista ei voida taata pelkästään automaattisesti Avoindata-palvelun puolesta, vaan tiedon avaajalla on tässä prosessissa merkittävä rooli: Millaista dataa avataan ja millä tavoin julkaistu data on kuvattu.
Kaikki FAIR-periaatteet on kuvattu tarkemmin alla olevassa taulukossa. Periaatteita ei ole suomennettu sanatarkasti. Käännöksessä on keskitytty asiasisällön esille tuomiseen. Niissä esitetään 10 tarkastus- ja mittauskriteeriä avoimelle datalle neljässä eri kategoriassa
| Osa-alue | Tarkistamiseen ja mittaamiseen liittyvät kriteerit |
|---|---|
|
Löydettävyys (Findable) |
1. Tietoaineistolla on yksilöllinen tunniste (engl. Persistent IDentifier, PID), joka toimii maailmanlaajuisesti ja on pysyvä. |
| 2. Tietoaineisto on kuvattu tämän taulukon kohdassa 10 määriteltyjen metatietoperiaatteiden mukaisesti ja riittävän kattavasti. | |
| 3. Tietoaineiston yksilöllinen tunniste (PID) on osa metatietoja. | |
| 4. Metatiedot on rekisteröity ja indeksoitu osaksi haettavaa resurssia. | |
|
Saavutettavuus (Accessible) |
5. Metatiedot ja tietoaineisto voidaan hakea standardoidun protokollan avulla. |
| 5a. Käytetty protokolla on avoin, maksuton ja maailmanlaajuisesti käytettävissä oleva. | |
| 5b. Protokolla tukee tunnistamista ja valtuuttamista, silloin kun ne ovat tarpeellisia. | |
| 6. Tietoaineiston metatietoja ei poisteta. Ne ovat saatavilla, vaikka tietoaineisto olisi poistettu. | |
|
Yhteentoimivuus (Interoperable) |
7. Metatiedot ja tietoaineisto käyttävät määrämuotoista, helposti saatavilla olevaa, jaettua ja laajasti sovellettavaa kieltä tiedon esittämiseen. |
| 8. Metatieto käyttää sanastoja, jotka noudattavat FAIR-periaatteita. | |
| 9. Metatiedot sisältävät määritellyt viittaukset muihin metatietoihin. | |
|
Uudelleen käytettävyys (Re-usable) |
10. Metatiedot kuvataan monipuolisesti tarkoilla ja osuvilla määritteillä. |
| 10a. Metatiedot ja tietoaineisto julkaistaan selkeällä tietojen käyttöluvalla eli lisenssillä. | |
| 10b. Metatietoihin on merkitty tietoaineiston alkuperäinen lähde luotettavasti ja tarkasti. | |
| 10c. Metatiedot ja tietoaineisto noudattavat oman aihepiirinsä hyviä käytäntöjä ja ohjeistuksia. |
Kitkattoman datapaketin malli
Kitkaton datapaketti (engl. Frictionless Data Package) on kansalaisjärjestö Open Knowledge Internationalin (OKI) vuonna 2016 luoma aloite. Sen tavoite on helpottaa datan uudelleenkäyttöä ja parantaa luotettavuutta luomalla sille avoin ja standardoitu pakattu-tiedosto-rakenne.
Tavoitteena on siis poistaa datan työskentelyyn liittyvää kitkaa (friction). Tyypillisiä datapaketin hyödyntäjiä ovat esimerkiksi tutkijat (tutkimusten automaattinen toistettavuus), datatieteilijät (datakäsittelyn automaattiset putkistot) ja datainsinöörit (datan standardisointi).
Rakenteellisessa ja avoimessa tiedostomuodossa oleva avoin data pakataan datapaketin (pakattu tiedosto, .zip) sisään. Sen sisältö (tietomalli) kuvaillaan skeemalla ja mukaan voidaan liittää vielä datan tarina, jonka avulla voidaan kertoa datan käyttökonteksti (auttaa ymmärtämään sitä, mistä data on kotoisin ja mihin sitä voi käyttää).
Aloitteessa on otettu esimerkkiä siitä, miten merikontit aikoinaan mullistivat tavaran kuljetuksen logistiikan ympäri maailmaa. Aina fyysisesti samankokoinen merikontti sopii laivoihin, juniin, rekkoihin ja merikontteja on helppo siirtää niiden välillä. Merikonttien avulla erilaisten tavaroiden liikuttelu pystyttiin standardoimaan maailmanlaajuisesti. Datapaketti pyrkii tekemään saman datalle ja poistamaan sen käsittelyyn liittyvää kitkaa. Esimerkiksi datan automaattinen käsittely, käsittely eri ohjelmilla jne.
Toisena esikuvana kitkattomalle datapaketille on Lego-palikat. Erilaiset legopalikat sopivat yhteen ja niitä on helppo yhdistellä suuremmaksi kokonaisuudeksi. Alla olevassa kuvassa on esitetty kitkattoman datapaketin malli.
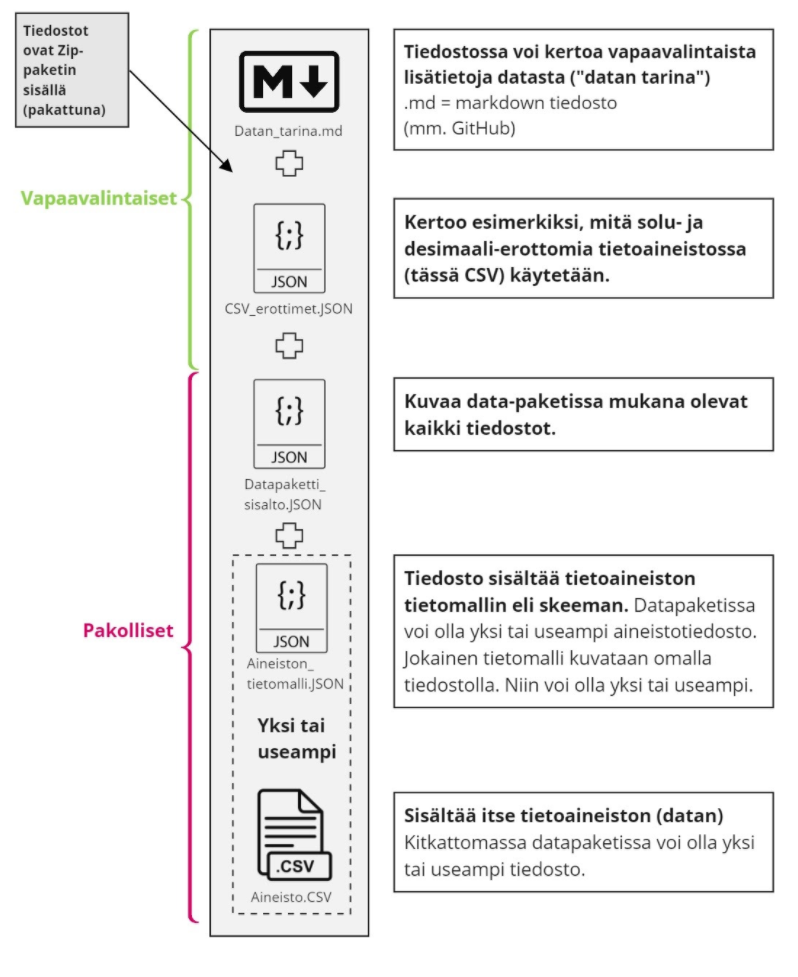
Kitkaton datapaketti voi sisältää useamman tietoaineiston. Tiedostoissa voi olla useita erilaisia tietomalleja. Jokainen tietomalli tulee kuvata omalla skeemalla. Kitkattoman datapaketin skeema ei sisällä semanttista yhteentoimivuutta. Sen avulla lähinnä kuvataan teknisesti muuttujia (string, int) ja nimiä. Alla on avattu esimerkin avulla kitkattoman datapaketin skeeman sisältöä.
Kitkattoman datapaketin sisältämän skeeman esimerkkisisältö (Schema.JSON):
"schema": {
"fields": [
{
"name":"Date", "type":"date", "format":"fmt:%d/%m/%Y"
},
{
"name":"Age", "type":"integer",
"constraints": {"minimum": 0, "required": "true"},
"missingValue": "NULL"
},
{
"name":"Primary Therapy Outcome",
"description": "Whether primary treatment success",
"type": "string",
"constraints": {"enum": ["PARTIAL","COMPLETE"]}
}
]
}
Kitkattoman datapaketin sisälle voidaan tallentaa useita erilaisia avoimia tiedostomuotoja. CSV-tiedostoja käytetään usein taulukkomuodossa olevan tiedon tallentamisessa ja käsittelyssä ja se on ollut kitkattoman datapaketin idean kehittämisessä keskiössä edellisten vuosien aikana.
Datapaketti on aina joku looginen kokoelma tietoa (avointa dataa).
Lisätietoja
Viiden ja seitsemän tähden mallit
Avoimen datan laatua on yritetty parantaa kansainvälisesti useilla eri tavoilla. World Wide Webin kehittäjä Tim Berners-Lee esitti vuonna 2009 oman mallinsa avoimen datan laadun kehittämiseen. Malli käydään läpi osana tätä teknistä viitekehystä, koska se on kansainvälisesti merkittävä. Esimerkiksi EU selvittää mallin käyttöä jäsenmaissa vuosittaisessa kyselyssään.
Berners-Leen malli tarjoaa ymmärrystä avoimen datan kehityksestä ja avaa eri tiedostomuotojen merkitystä osana datan avaamisen kehityskulkua. Mallin taustalla on halu edistää linkitetyn datan käyttöä. Mallin tasot 4 ja 5 ovat kuitenkin herättäneet laajaa keskustelua. Kaikki eivät kannata linkitettyyn dataan johtavaa avoimen datan kehitystä, koska se saattaa tehdä jossain tapauksissa datan hyödyntämisestä vaikeampaa. Berners-Leen malli on avattu alla olevassa taulukossa.
| Taso | Tähdet | Vaatimus | Käytännön esimerkki |
|---|---|---|---|
| 5 | ★★★★★ | Edellisten vaatimusten lisäksi tietoaineistossa on linkkejä toisiin, sen ulkopuolisiin avoimen datan aineistoihin. Näin tietoaineiston avulla voi selailla siihen liittyvää avointa tietoa verkostomaisesti. | Tietoaineistojen välillä voi liikkua ja eri aineistot muodostavat kokonaisuuden. Esimerkiksi https://lod-cloud.net/-sivusto visualisoi linkitettyä dataa. |
| 4 | ★★★★ | Edellisten vaatimusten lisäksi datassa on yksilöllinen ja elinikäinen tunniste ja tietoaineiston sisälle voi viitata eri kohtiin. |
Usein RDF tai SPARQL. SPARQL on W3C-standardoitu kyselykieli RDF-tietokantaan. Esimerkiksi taulukon muotoinen data, joka yksittäisiin soluihin voi viitata. |
| 3 | ★★★ | Edellisten vaatimusten lisäksi tietoaineisto on saatavilla avoimessa tiedostomuodossa | Tietoaineiston jakelu on esimerkiksi CSV-muodossa (comma-separated values) |
| 2 | ★★ | Edellisten vaatimusten lisäksi tietoaineisto on saatavilla rakenteellisessa muodossa. | Esimerkiksi Microsoft Excel, PowerPoint ja Word. Esimerkiksi taulukko, joka on skannattu kuvaksi, ei ole rakenteellisessa muodossa, mutta Microsoft Excel on. |
| 1 | ★ | Data on internetissä saatavilla missä tahansa tiedostomuodossa ja sen käyttölupa eli lisenssi on avoin. | Tyypillisesti aineisto on PDF-tiedostomuodossa. |
Kaikki Avoindata-palvelussa julkaistu data sijoittuu tässä mallissa vähintään tasolle 1, eli datan käyttölupa mahdollistaa datan avoimen käytön. Avoindata-palvelu suosittelee, että vähintään yksi (1) tietoaineiston jakelumuodoista täyttäisi vähintään tason 3 vaatimukset.
Suomalaiset Aalto-yliopiston semanttisen internetin tutkijat Eero Hyvönen, Jouni Tuominen, Miika Alonen ja Eetu Mäkelä esittivät vuonna 2014 täydennystä Tim Berners-Leen alkuperäiseen viiden tähden malliin kahdella lisätähdellä. Alkuperäisessä mallissa voidaan viiden tähden tasolla käyttää mitä tahansa sanastoa ja tietomallia.
Mallia täydentävässä esityksessä tasolla 6 avoimen datan tietomalli perustuu johonkin yleisesti saatavilla olevaan semanttiseen tietomalliin. Keskeinen ero on silloin se, että samaa tietomallia käytetään yleisesti ja useissa eri toimijoiden tekemissä datan avauksissa sen sijaan, että jokainen tekisi oman tietomallinsa uuden tiedon avaamisen yhteydessä. Tasolla seitsemän (7) tietosisällön voi testata automaattisesti tietomallia vasten. Eli varmistaa, että tieto vastaa ilmoitettua tietomallia.
| Taso | Tähdet | Vaatimus | Käytännön esimerkki |
|---|---|---|---|
| 7 | ★★★★★★★ | Edellisten vaatimusten lisäksi tietoaineiston sisältö voidaan testata koneellisesti tietomallia vasten. | |
| 6 | ★★★★★★ | Edellisten vaatimusten lisäksi datassa ei voi käyttää itse keksittyä tietomallia. Datassa käytettävän tietomalli pitää olla laajasti tunnettu. | Tietomalli on esimerkiksi EU-maiden yhteinen (korkean lisäarvon tietoaineistot) tai pohjautuu esim. Schema.org tietomalliin. |
Yhteenveto
Tim Berners-Leen alkuperäinen viiden tähden malli keskittyy käyttöluvan avoimuuteen (lisenssi), tiedostomuodon avoimuuteen ja avoimeen rakenteeseen (tietoalkioiden osoittaminen). Eero Hyvösen, Jouni Tuomisen, Miika Alonsen ja Eetu Mäkelän tekemä esitys mallin laajentamisesta ottaa näiden lisäksi laajemman semanttisen yhteentoimivuuden ja tietoaineiston automaattiseen testattavuuden mukaan. Testattavuuden avulla voidaan selvittää, että data noudattaa ilmoitettua tietomallia (skeemaa). Suomessa on myös kehitetty yhteentoimivuusalustaa, joka pyrkii lisäämään tiedon semanttista yhteentoimivuutta.